
|
Michael S. Ryoo Ph.D. Senior Staff Research Scientist Google DeepMind Robotics SUNY Empire Innovation Associate Professor Department of Computer Science; AI Institute Stony Brook University Contact mryoo-at-cs.stonybrook.edu |
I re-joined Google DeepMind Robotics in March 2026. Prior to that, I was with Salesforce AI Research for ~2 years, and was with the robotics team at Google DeepMind (and formerly Google Brain) for 5.5 years. I also hold a tenured position in the Department of Computer Science (CS) at Stony Brook University as an associate professor. Previously, I was an assistant professor at Indiana University Bloomington, and was a staff researcher within the Robotics Section of the NASA's Jet Propulsion Laboratory (JPL). I received my Ph.D. from the University of Texas at Austin in 2008 and B.S. from Korea Advanced Institute of Science and Technology (KAIST) in 2004.
Recent News
 |
2026/02 Introducing Motion World Models for Robot Control ! It's a paradigm to predict 'future motion', for better robot actions. |
 |
2025/09 Pixel Motion Diffusion is What We Need for Robot Control ! The approach is named DAWN (Diffusion is All you Need for robot control), as it uses two different types of diffusions (motion image diffusion and diffusion policy). The paper will also appear at CVPR 2026. |
 |
2025/09 Organized CoRL 2025 in Seoul, Korea as a general chair. |
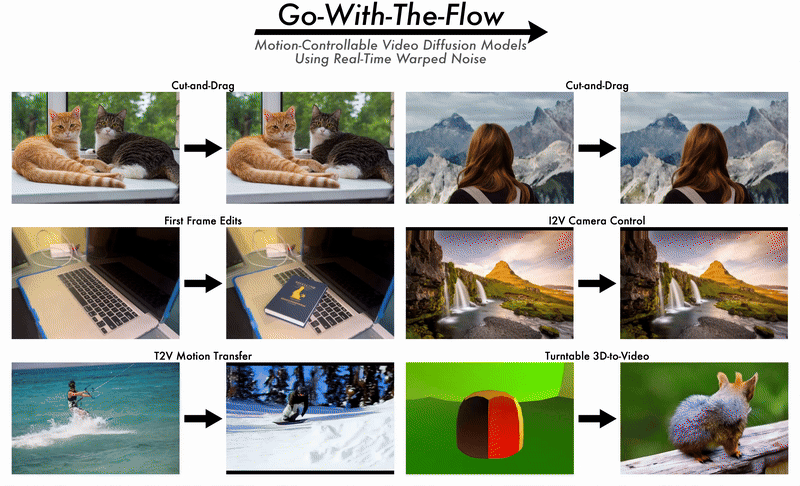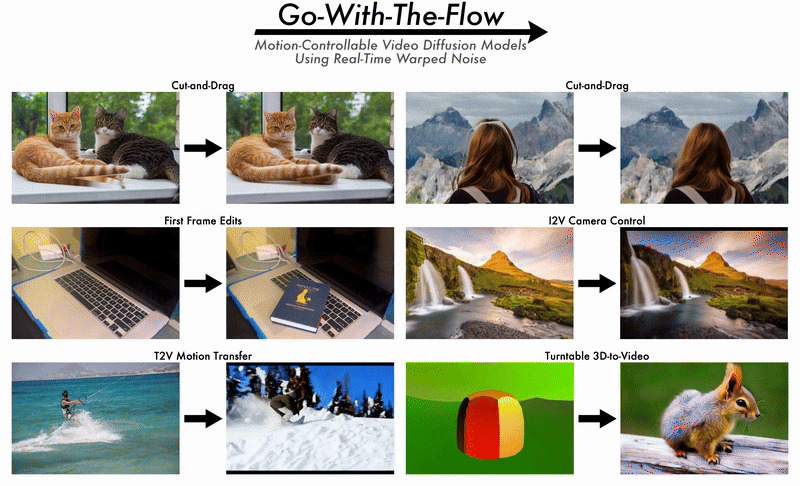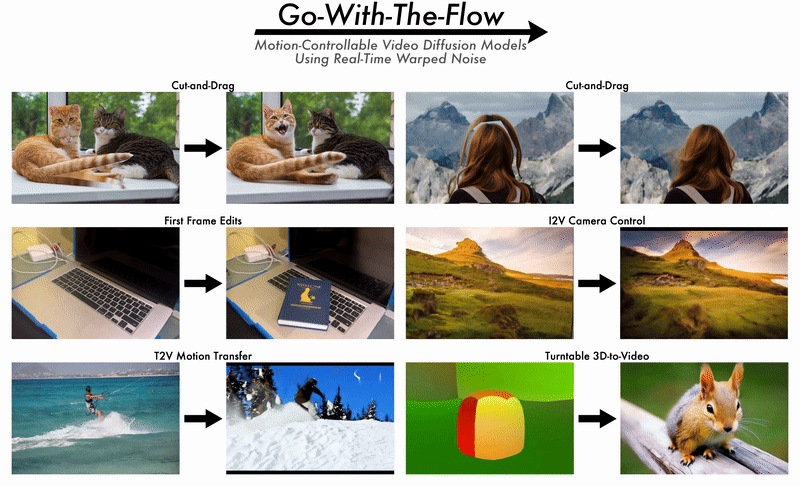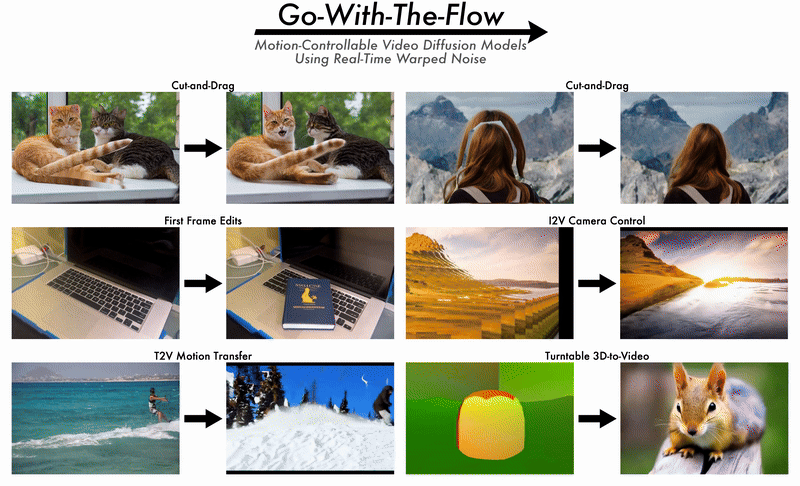 |
2025/06 Ryan's paper on Go-with-the-Flow will be presented at CVPR 2025 as an oral paper. |
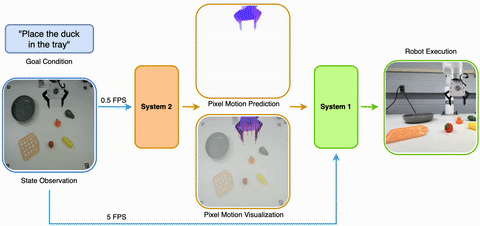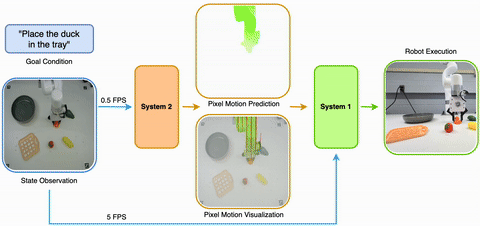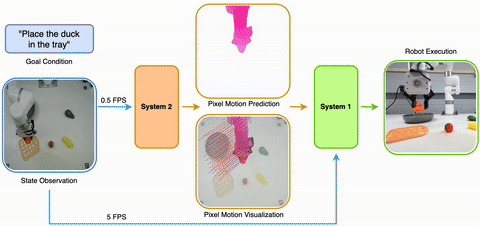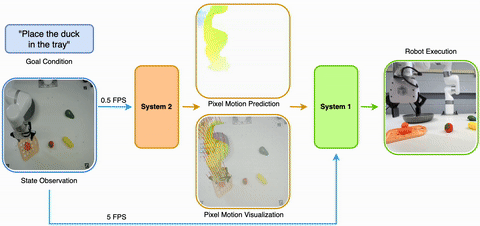 |
2025/05 Introducing LangToMo, learning to use pixel motion forecasting as (universal) intermediate representations for robot control. It is a new System1-System2 architecture using image diffusion model as high-level System2 and Transformer as System1. |
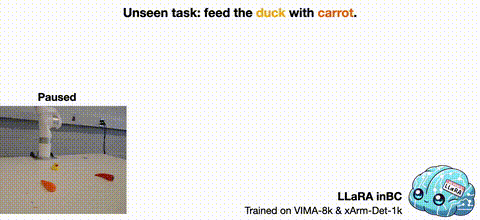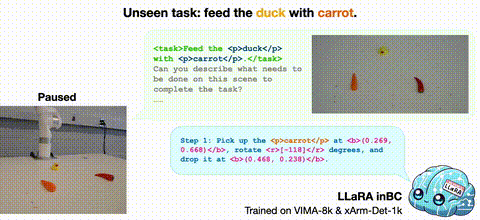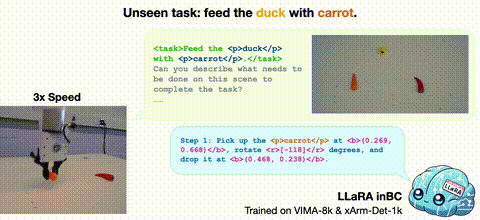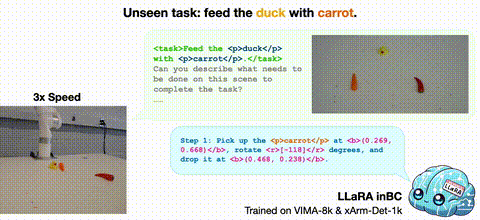 |
2025/01 Introducing LLaRA: Supercharging Robot Learning Data for Vision-Language Policy, to appear at ICLR 2025! It is a framework for an efficient transformation of a VLM into a robot Vision-Language-Action (VLA) model. |
 |
2024/10 BLIP-3-Video is out! It is an efficient multimodal language model designed for videos. Compared to other models, xGen-MM-Vid represents a video with a fraction of the visual tokens (e.g., 32 vs. 4608 tokens). |
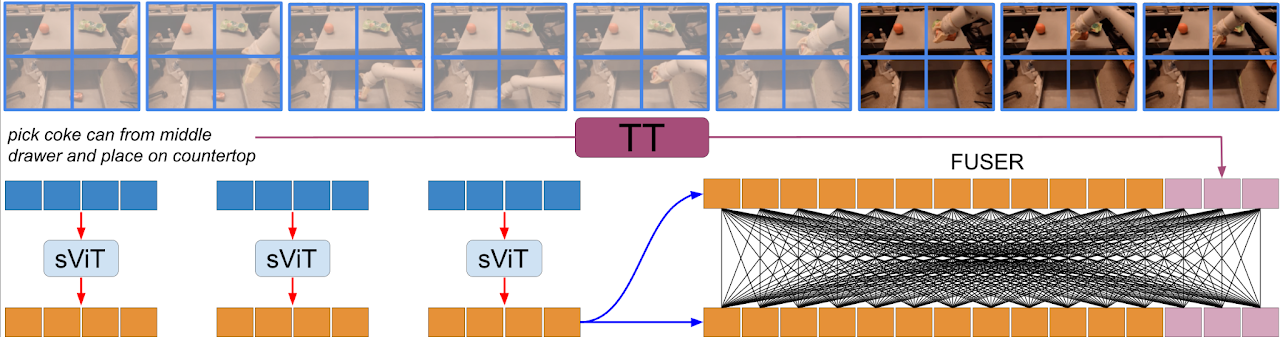 |
2024/05 SARA-RT: Scaling up Robotics Transformers with Self-Adaptive Robust Attention received the Best Paper Award in Robot Manipulation at ICRA 2024. |
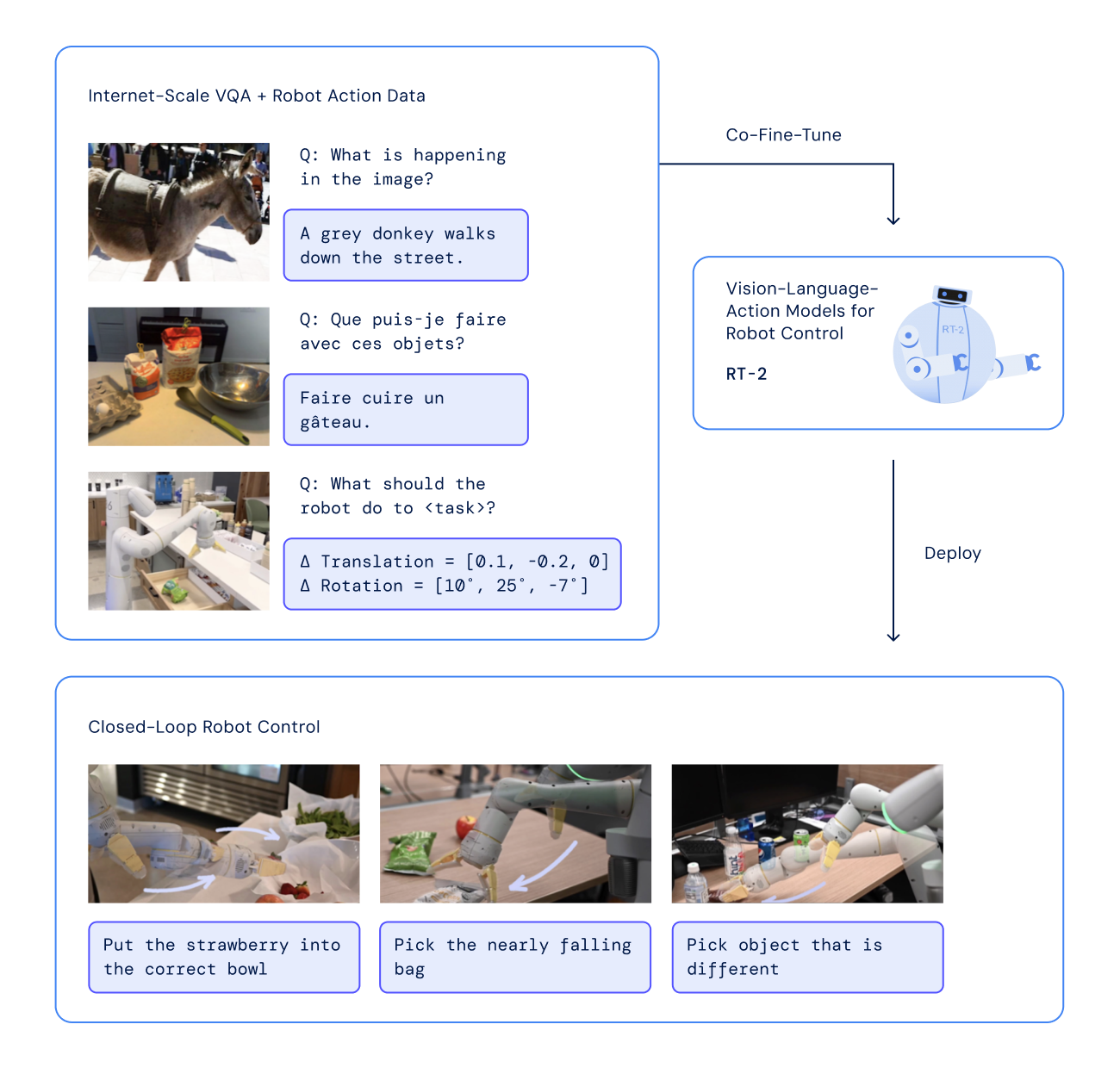 |
2023/09 RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control at CoRL 2023! |
 |
2023/07 Diffusion Illusions: Hiding Images in Plain Sight received CVPR 2023 Outstanding Demo Award. It is based on the same lossed used in Peekaboo: Text to Image Diffusion Models are Zero-Shot Segmentors |
 |
2023/07 RT-1: Robotics Transformer for Real-World Control at Scale at RSS 2023! |
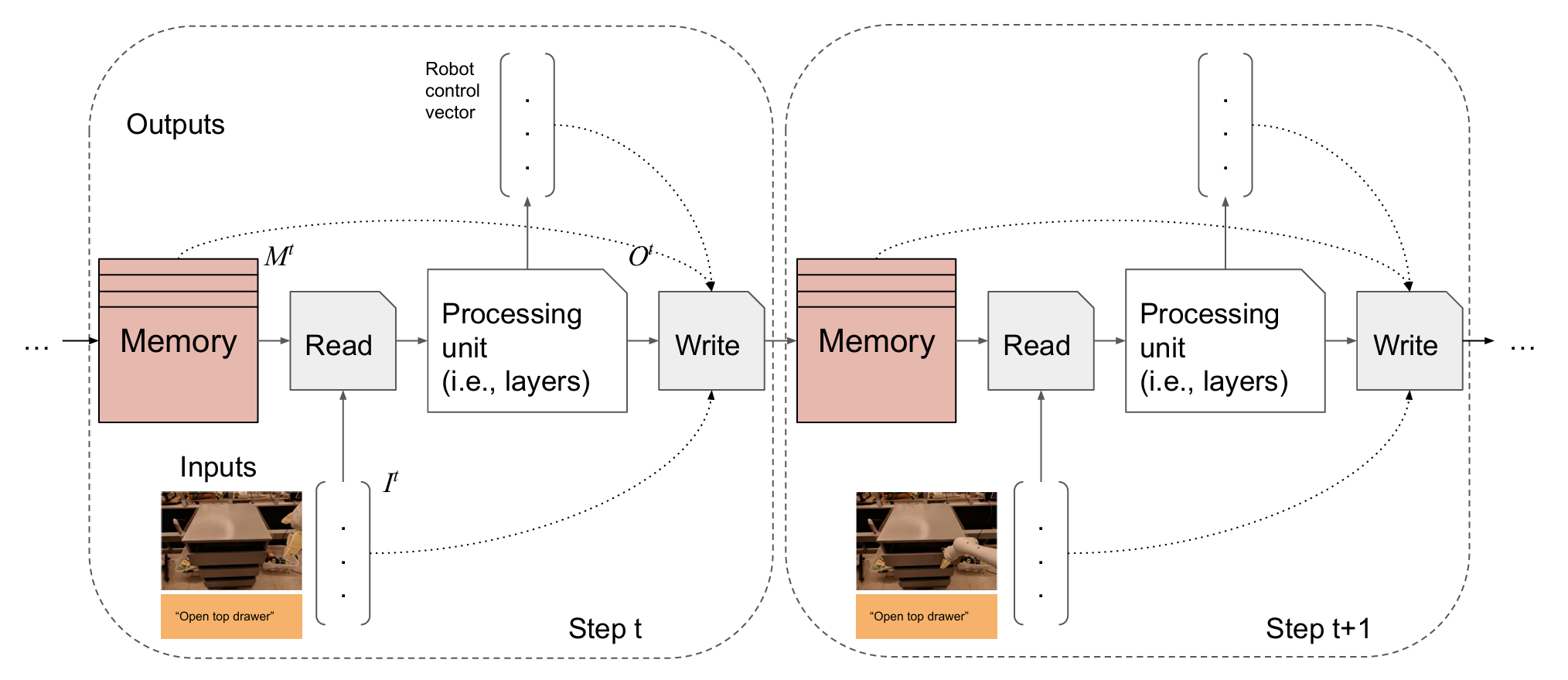 |
2023/06 Token Turing Machines, a new sequential model modernizing Neural Turing Machines was presented at CVPR 2023. [video] |
 |
2021/06 Check TokenLearner for images and videos! It learns to adaptively generate a small number of tokens for Transformers, providing better accuracies while also being faster. The paper also appeared at NeurIPS 2021. |
Curriculum Vitae pdf
Publications [by type] [by year]
List of selected publications
- Nguyen, Zhang, Ranasinghe, Li, Ryoo, Pixel Motion Diffusion is What We Need for Robot Control , CVPR 2026
- Li et al., LLaRA: Supercharging Robot Learning Data for Vision-Language Policy, ICLR 2025
- Ranasinghe, Li, Kahatapitiya, Ryoo, Understanding Long Videos in One Multimodal Language Model Pass, ICLR 2025
- Ryoo et al., xGen-MM-Vid (BLIP-3-Video): You Only Need 32 Tokens to Represent a Video Even in VLMs, arXiv:2410.16267
- Burgert, Li, Leite, Ranasinghe, Ryoo, Diffusion Illusions: Hiding Images in Plain Sight, SIGGRAPH 2024
- Piergiovanni et al., Mirasol3B: A Multimodal Autoregressive Model for Time-aligned and Contextual Modalities, CVPR 2024
- Researchers in Google DeepMind Robotics, RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control, CoRL 2023
- Shang and Ryoo, Active Vision Reinforcement Learning under Limited Visual Observability, NeurIPS 2023
- Ryoo, Gopalakrishnan, Kahatapitiya, Xiao, Rao, Stone, Lu, Ibarz, Arnab, Token Turing Machines, CVPR 2023
- Researchers in Robotics at Google, RT-1: Robotics Transformer for Real-World Control at Scale, RSS 2023
- Burgert, Shang, Li, Ryoo, Neural Neural Textures Make Sim2Real Consistent, CoRL 2022
- Li, Shang, Das, Ryoo, Does Self-supervised Learning Really Improve Reinforcement Learning from Pixels?, NeurIPS 2022
- Ryoo, Piergiovanni, Arnab, Dehghani, Angelova, TokenLearner: Adaptive Space-Time Tokenization for Videos, NeurIPS 2021
- Akinola, Angelova, Lu, Chebotar, Kalashnikov, Varley, Ibarz, Ryoo, Visionary: Vision Architecture Discovery for Robot Learning, ICRA 2021
- Piergiovanni, Angelova, Ryoo, Evolving Losses for Unsupervised Video Representation Learning, CVPR 2020
- Ryoo, Piergiovanni, Tan, Angelova, AssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures, ICLR 2020
- Piergiovanni, Angelova, Ryoo, Differentiable Grammars for videos, AAAI 2020
- Piergiovanni, Wu, Ryoo, Learning Real-World Robot Policies by Dreaming, IROS 2019
- Piergiovanni and Ryoo, Temporal Gaussian Mixture Layer for Videos, ICML 2019
- Piergiovanni and Ryoo, Representation Flow for Action Recognition, CVPR 2019
- Ren, Lee, Ryoo, Learning to Anonymize Faces for Privacy Preserving Action Detection, ECCV 2018
Datasets
AViD dataset: Anonymized Videos from Diverse Countries.MLB-YouTube dataset: an activity recognition dataset with over 42 hours of 2017 MLB post-season baseball videos.
JPL-Interaction dataset: a robot-centric first-person video dataset.
DogCentric Activity dataset: a first-person video dataset taken with dogs.
UT-Interaction dataset: a dataset containing continuous/segmented videos of human-human interactions.
Lab members
Cristina Mata (Stony Brook University CS)Xiang Li (Stony Brook University CS)
Jongwoo Park (Stony Brook University CS)
Ryan Burgert (Stony Brook University CS)
Abe Leite (Stony Brook University CS)
Yichi Zhang (Stony Brook University CS)
Yoosung Jang (Stony Brook University CS)
E Ro Nguyen (Stony Brook University CS)
Alumni
Kanchana Ranasinghe (PhD 2026; joined Salesforce AI Research)Kumara Kahatapitiya (PhD 2025; joined Meta)
Jinghuan Shang (PhD 2024; joined Boston Dynamics AI Institute)
Alan Wu (PhD 2023; returned to MIT Lincoln Lab)
Srijan Das (PostDoc 2022; joined UNC Charlotte)
AJ Piergiovanni (PhD 2020; joined Google Brain)
Teaching
CSE378: Intro to Robotics (Fall 2023)CSE525: Robotics (Spring 2023)
CSE527: Intro to Computer Vision (Fall 2021)
B457/I400: Intro to Computer Vision (Spring 2018)
B659/I590: Vision for Intelligent Robotics (Fall 2017)
Updated 03/2026